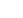

Machine learning is a type of artificial intelligence that focuses on software having the ability to learn without being explicitly programmed to do so, essentially self-learning, by detecting patterns in data sets.
Supervised Learning
In this type of machine learning, the algorithm looks at the past data of labeled inputs, called a training set, and applies the patterns detected to new data to create a general rule for mapping inputs to outputs.
Unsupervised Learning
In this type of machine learning, algorithms aren't provided labels for the data and therefore must draw inferences from the datasets to find hidden patterns and thereby group the data. For example, I've used this in the past on a hospital's purchasing data and it'll be able to group most of the inventory into surprisingly good groupings by analyzing the item's attributes. The pediatrics items will have distinctive enough attributes to group separately from orthopedics, while surgical and emergency items may share significant overlap and not group separately by themselves. I've found this to be more time consuming for analysis than other types, yet has the ability to find amazing patterns and insights from data that are unexpected, but can yield enormous potential. This type is often used on more technical data analysis, anomaly detection and has had a considerable impact on counter-terrorism over the past many years.
Reinforcement Learning
This type of machine learning focuses on performing an action in an environment with the goal of maximizing reward. A passion of mine is mobile robotics and while I'm still in the early stages of development on some prototypes, reinforcement learning is the fundamental method that guides their activities. For example, a robot's goal might be to explore and find the most efficient route, which is called path minimization, between two locations. The environment and the action of navigating through it, teaches the robot and it'll learn to find shortcuts from analyzing small deviations to its route, until it finds the most efficient route.
A Real-Life Example
A "recommender system", which is software that makes a recommendation of activity to a user based on an analysis of attributes and/or past history for the user, is a good example of this in real-life. A year ago I worked on one for an organization that wanted to simplify supply chain operations for front-line employees. The organization had a custom, intranet application for procurement that presented the user with 100,000 possible SKUs from which to purchase. We added a recommender system that analyzed their past purchases and other purchases by individuals at their level and within their department, to show those results first on the auto-complete. This sort of implementation has the ability to reduce ordering time by more than 90% and considerably improves employee happiness (if you're purchasing a lot of items every day, spending ten seconds instead of three minutes per item will really make you much happier with your job).
Visual Example
In the example below, the data is unstructured and would rely upon other attributes if attempting to structure using unsupervised learning.

However, let's provide labels and structure the data so that we can use supervised machine learning. Now we've labeled the data points by color.
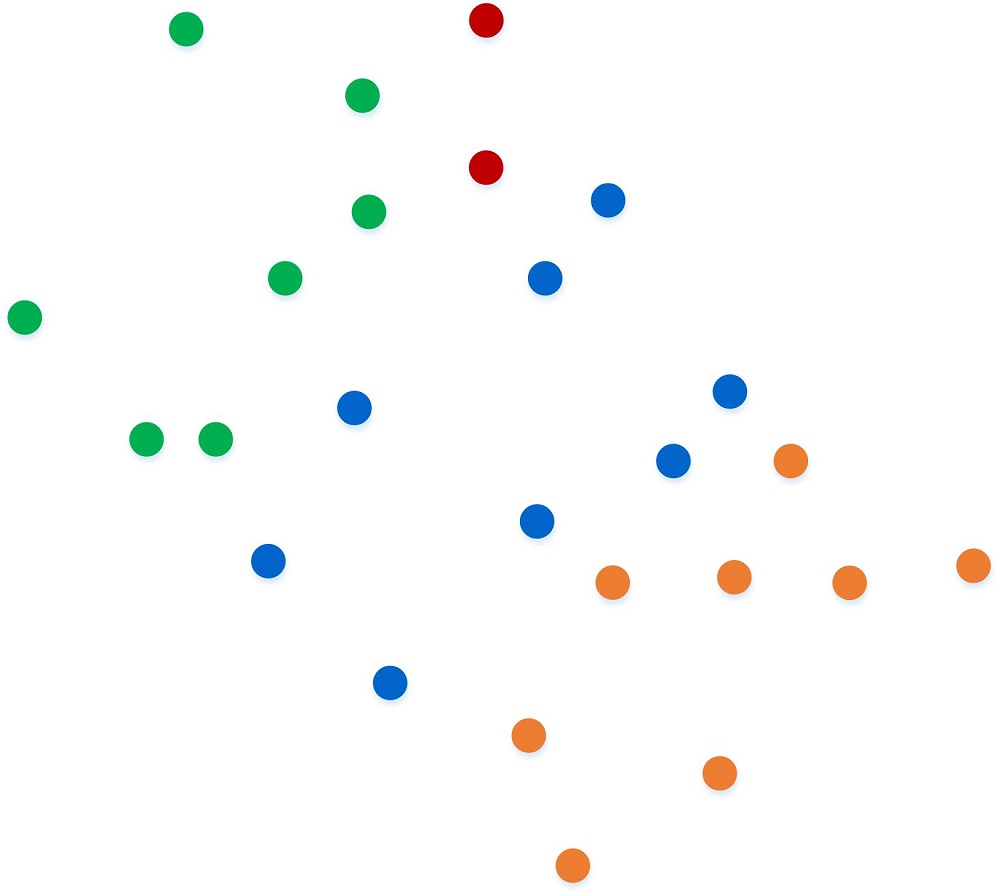
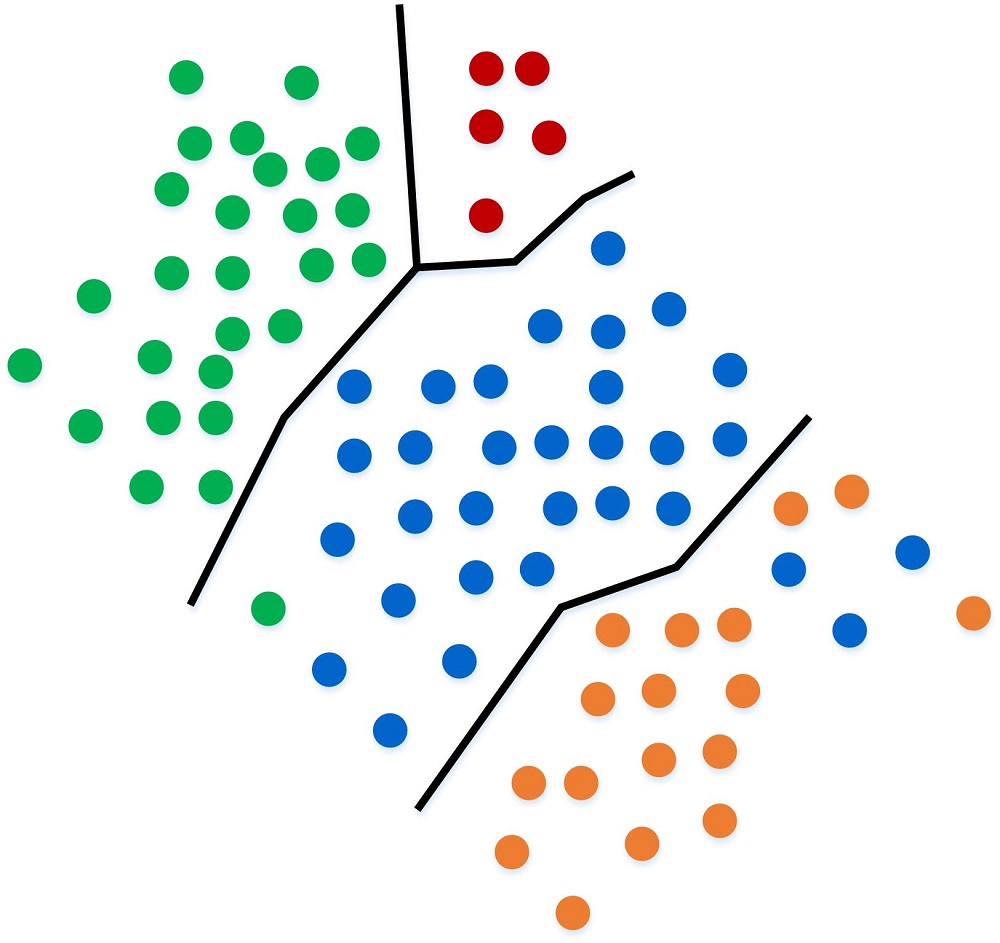
Using the training set provided, the algorithm can create a general rule in anticipation of future data points.
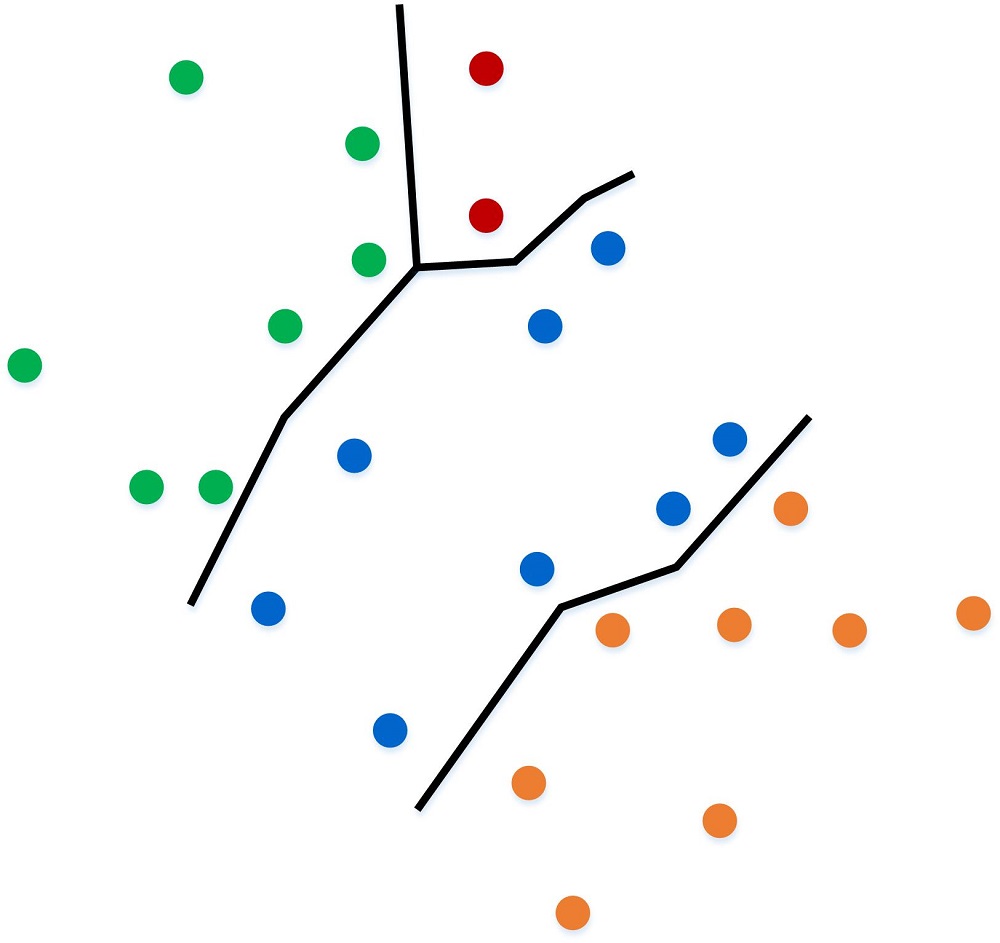
As more data points fill in, the algorithm can immediately label them in accordance with the rule it built off of the training set.
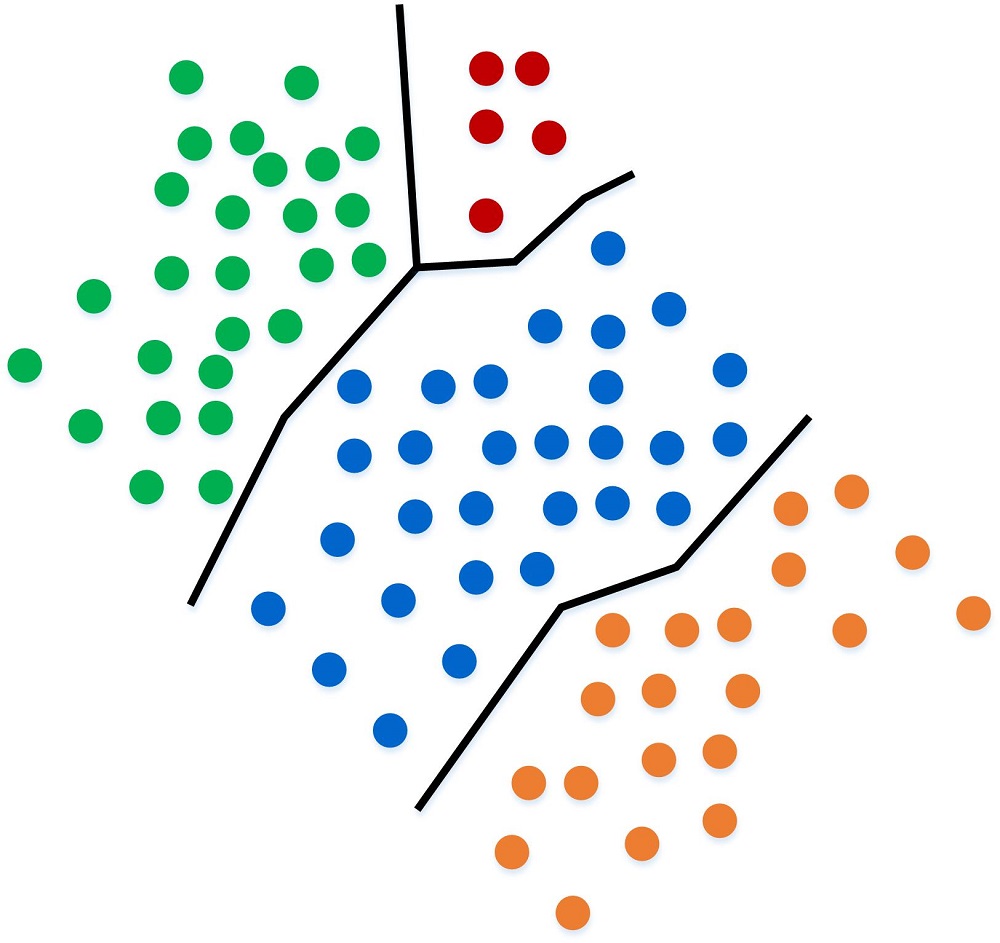
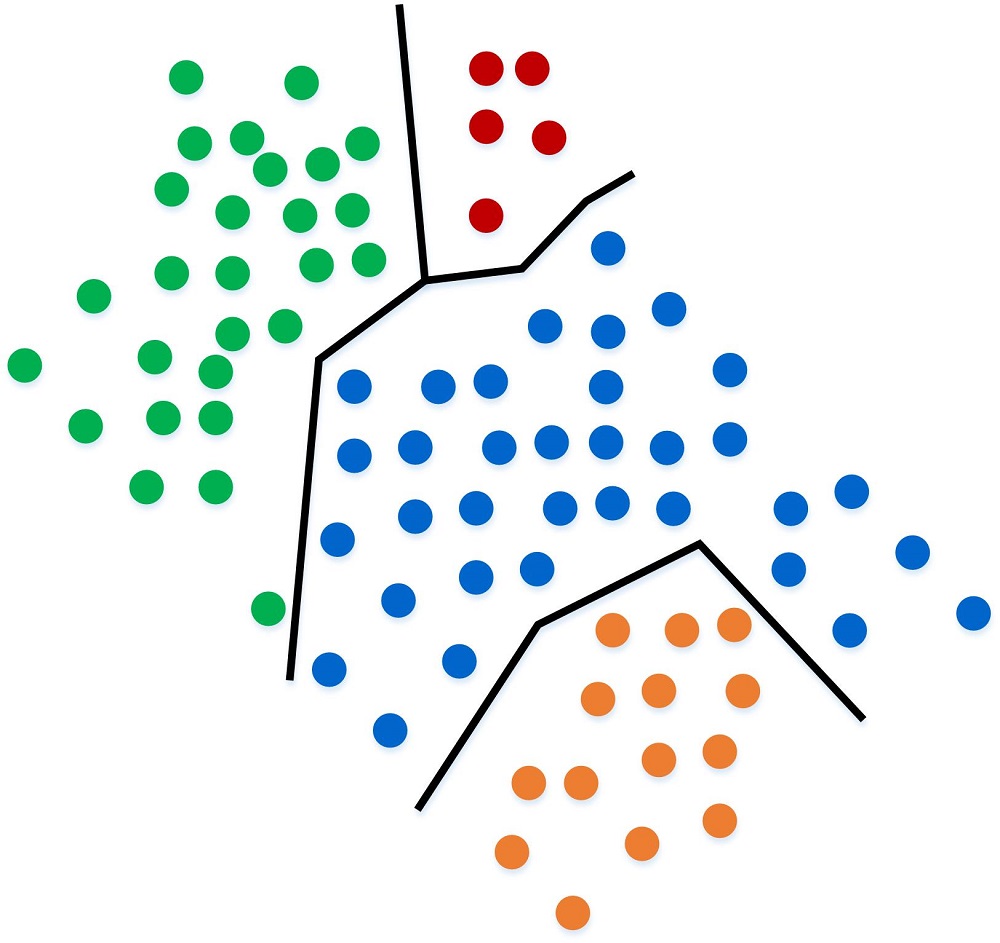
Now, let's pretend that we want to override the rule and reassign a category. This always happens in real-life, as the rule isn't perfect, well at least in the beginning. So we change one of the blue to green and then change three orange to blue.
The algorithm simply adjusts the rule to take into account the updated training set.
Conclusion
Machine learning has enormously potential and is in many of the cutting-edge systems in use, and development, today. Imagine on a large scale just how quickly and effectively this could process data, as well as how this will impact many over the upcoming decades. Once implemented, it is far less costly than having people doing the work. A couple years ago, I built a system for an organization that was doing $5 million in purchasing per day. They had thirty full-time people who categorized the daily purchases into their business intelligence system at an accuracy rate of 85%. Utilizing machine learning, we build a system with a training set of 0.5% of the transactions that was capable of accuracy upwards of 99.5%, while operating at a very small fraction of the cost.