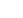

When we started Infinite AI, I was the only software engineer and software deployments weren't too much trouble, since there was very little software to deploy.
The Beginning
For those unfamiliar, the deployment of software code manually to servers is a very error prone process and typically fairly labor intensive. While I'm sure I'll get plenty of arguments from some on this, I'd estimate more than 80% of all companies developing applications lack automated software deployment and release management systems. Outside of the coasts, hence places like Indiana, it is upwards of 95%. I constantly run into companies in the region that have successfully completed Series A onwards that have tens of millions in cash, but haven't invested in any release management systems at all, as well as way, way too many firms out here that haven't even adopted a source control system...
Internal Development vs Consultants
Once we started hiring software engineers, deploying code suddenly became a major bottleneck. With a lot of time pressures, we began looking for someone to help us implement, from the ground up, a highly efficient and scalable release management system. We found a great consulting firm, well regarded by many individuals we knew and respected, and they bid competitively with others at a single project implementation that would take around two months (between our schedules) and would cost around $50k. That may surprise some, but it is a highly specialized field.
Product
After comparing numerous products, we decided to adopt Microsoft's Release Management, which had just been recently acquired by Microsoft from InCycle Software. We were very stratified with this choice.
Continuous Integration
We knew we wanted to adopt "Continuous Integration", which is the practice of merging all of the check-ins from all of the developers and deploying it upon every check-in. In my opinion, this should be the gold standard that organizations strive to achieve.
Our Goals for Release Management
- Everything starts with source control. Use it. Trust it. Keep learning more about it.
- A build should happen without anything other than checking in code.
- A build will happen on every check-in.
- Everyone needs to check-in at least daily.
- A build should have all unit, functional and integration tests run. If any fail, the build should fail and not deploy.
- Keep a close feedback loop by ensuring enough resources that a build will happen within three minutes of a check-in.
- We will use multiple stages as an initial build cannot go to users.
- Make the current build status obvious by using a build screen and notifiers on the taskbar.
- Only allow the head of software or QA to override these policies on a case-by-case basis.
Moving Forward
Having worked on ancillary tasks and having experience with administering TFS, I decided to dedicate a couple of weeks of reading and watching a lot of presentations on best practices. I then setup a test environment and started moving forward on building the system. It was a painful process, but I learned a lot and soon the organization full adopted it.
Running Tests on Check-in
We setup the system so that all unit, functional and integration tests associated with it would run on every check-in. This was painful at first, but ultimately led to much better code quality.
Stages
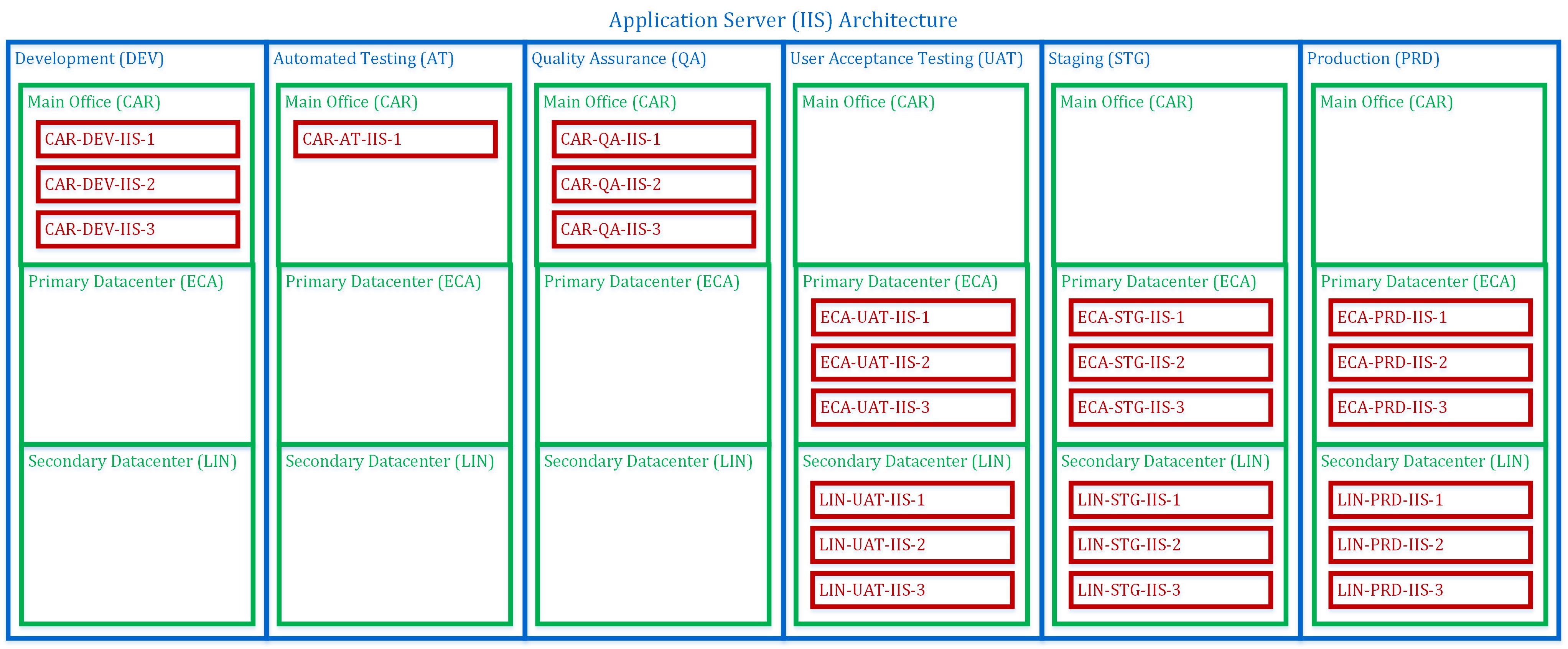
We built it in a very comprehensive way from the start, across six stages: Development, Automated Testing, Quality Assurance, User Acceptance Testing, Staging and Production.
Servers
We worked with our Computing Team to know what servers would be needed to operate the various software applications in development. We installed agents on all of the SQL and IIS servers, which allowed very fast deployments of code to each stage. The company used SQL Server 2014 Enterprise with AlwaysOn and our application server were IIS. We used a custom PowerShell script to deploy the application code and DACPAC to update the database.
Nightly Build
Not only is there a build on every check-in, but we also setup a nightly build as well. Since this would still run all unit, functional and integration tests, we had the potential to catch issues that weren't found on check-in. Surprisingly, we found a lot more that way than I would have expected. Sometimes someone would change a database column or something outside of version control and it'd crash overnight.
Deployment Efficiency
It varied by the day, but at times we pushed through a lot of code. On some days, we would achieve ten or more pushes to a stage per hour. If considering the multiple servers per stage, that means we were deploying to 30 or more servers within an hour. This would take no human interaction and we eventually got to less than a 1% failure rate on deployments.
Automated Testing
We tried to use Ranorex, but we often found it was cumbersome and challenging for it to keep up. I'm aware there are various means by which to set it up, but we never found a great solution after trying various configurations for a few months. This isn't to say it didn't work at all, it was just not perfect by any means. It was certainly the best of the five products that we tested out.
Conclusion
Ultimately, we were very happy with the adoption of Release Management. Every time I work on software delivery and build automation projects, they yield absolutely great return on investments. The software team is happier, computing is happier, customers are happy and confident their software will work, project managers get more visibility and stability, and the business gets huge time savings.